QLoRA: 16-bit의 성능을 유지하면서 65B개의 파라미터를 가진 모델을 Single 48GB GPU에 올려 finetuning 할 수 있게 한다.
# Contribution
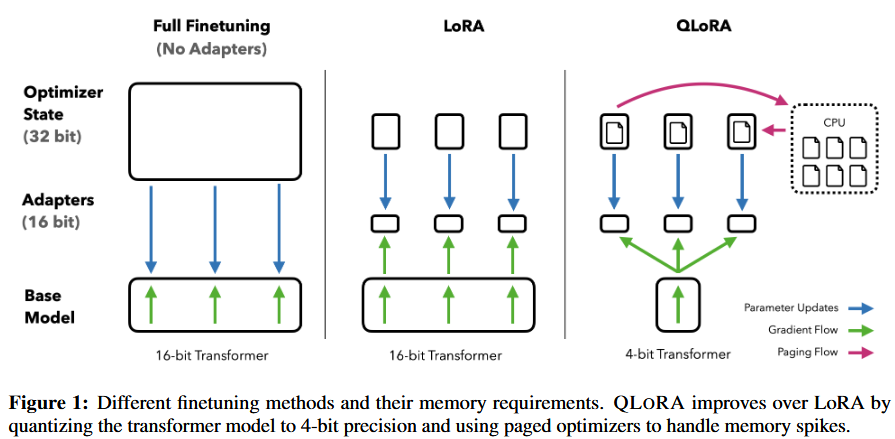
QLoRA 방법론
1. 4-bit NormalFloat(NF4): 정규분포된 가중치에 대해 정보 이론적으로 최적인 새로운 데이터 타입
2. Double Quantization: 양자화 상수를 다시 양자화함으로써 평균 메모리 사용량 절감
3. Paged Optimizers: 메모리 사용량이 급증하는 상황을 효과적으로 제어
# Introduction
LLM을 Finetuning 하는건 특정 도메인에서의 성능을 향상시키기 위해 필요한 과정이다.
기존에는 16-bit finetuning을 하기 위해서는 LLaMA 65B 기준으로, 780GB 크기의 GPU 메모리가 필요하였다.
그러나 QLoRA는 runtime이나 predictive performance의 성능 저하 없이도 오직 48GB 크기의 메모리만 필요하다.
위의 contribution에서 얘기했듯이 핵심은 세가지다.
1. 4-bit NormalFloat
기존의 4-bit quantizaiton 방식인 4-bit Integer, 4-bit Float quantization 방식은 균등하게 간격을 나누지만, 대부분 weight 는 정규분포 (normal distribution, N(0, σ²)) 를 따른다.
비트마다 표현하는 값의 범위를 "균등"하게 나누기보다는, 실제 분포에 맞게 값이 많이 몰린 부분에 비트를 더 할당하는 방식이 바로 4-bit NormalFloat이다. 정규 분포에 최적화되었기에 적은 비트로도 높은 정확도를 유지한다.
2. Double Quantization
원래 양자화(quantization)는 파라미터 값을 압축하는 방법인데,
QLoRA 는 한 단계 더 나아가서 양자화에 사용되는 상수들조차 다시 양자화한다.
이를 통해 파라미터당 평균 0.37bit 정도를 절감할 수 있으며, 대규모 모델 (예: 65B 모델) 에서는 약 3GB 메모리를 아낄 수 있다.
3. Paged Optimizers
기존 Optimizer는 mini-batch 크기가 커지거나 시퀀스 길이가 길어지면 메모리 사용이 폭발한다.
특히 gradient checkpointing 같은 기술을 사용할 때 메모리 spike 현상이 생긴다.
따라서 NVIDIA의 Unified Memory 기능을 활용해서 optimizer state 를 CPU 메모리로 넘겨 사용한다.
새로운 발견
1. 데이터 품질이 양보다 훨씬 중요하다
9k sample dataset(OASST1)은 450k sample dataset(FLAN v2, subsampled)보다 챗봇 성능에서 더 좋았다.
2. MMLU 성능이 챗봇 성능을 보장하지 않는다
MMLU (Massive Multitask Language Understanding) 벤치마크에서 점수가 높다고 해서 Vicuna 같은 챗봇 벤치마크에서 무조건 잘하는 것은 아니었다.
추가 분석
사람 평가자 + GPT-4 를 함께 사용해서 토너먼트 방식으로 모델들을 서로 대결시켜 평가했다. (주어진 프롬프트에 대해 어느 모델이 더 나은 답변을 생성하는지)
토너먼트 결과는 Elo 점수로 집계되어 챗봇의 성능 순위가 매겨진다.
결과는 대체로 GPT-4와 사람 평가가 일치하였지만, 그렇지 않은 경우도 있었다.
# Background
Block-wise k-bit Quantization
데이터를 더 적은 비트 수로 표현하는 방법이다.
데이터 전체에서 가장 큰 값으로 정규화(normalize) 하고 스케일링(scale) 해서 8비트로 표현

단점
만약에 입력 데이터 중에 너무 큰 값 (outlier, 이상치) 이 있으면,
전체 데이터를 최대값에 맞춰 정규화하기 때문에:
- 대부분의 "평범한 값들" 은 양자화 범위의 아주 좁은 부분에 몰리게 된다.
- 반면에 큰 값 (outlier) 때문에 양자화 비트 (quantization bins) 가 제대로 활용되지 않게 된다.
ex.
$X^{FP32} = [2.0,-1.0,0.0,8.0]$
$absmax(X^{FP32}) = max(|2.0|,|-1.0|,|0.0|,|8.0|) = 8.0$
해결책
데이터를 블록(block) 으로 나누고, 각 블록마다 따로 양자화 하는 방식을 사용한다.
블록마다 각각 최댓값을 기준으로 정규화하므로 outlier의 영향을 줄이고 비트 조합을 더 잘 활용할 수 있다.
Low-rank Adapters
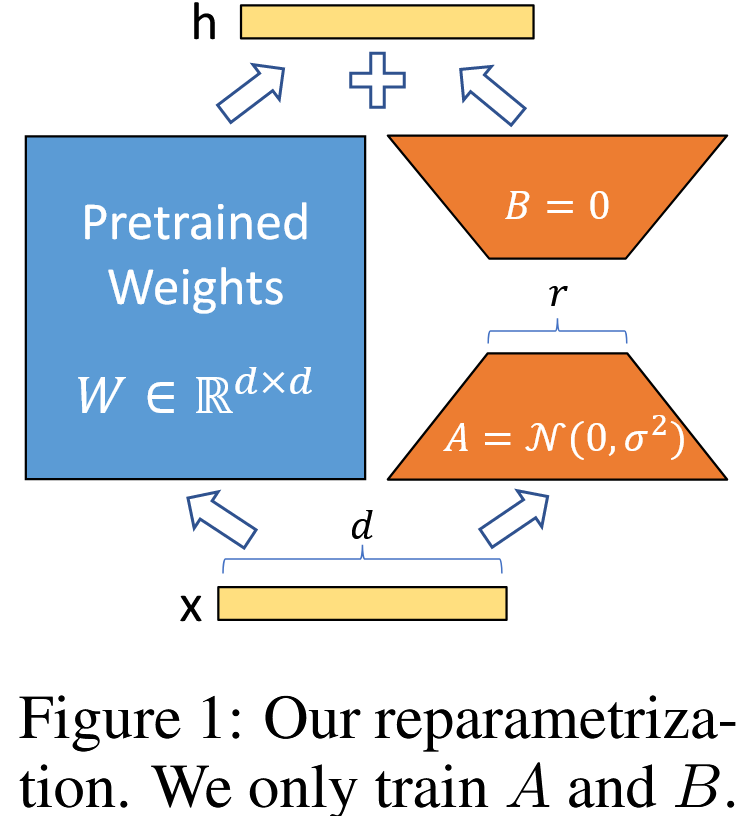
기존 큰 모델 파라미터들은 그대로 두고, 작고 학습 가능한 "Adapter (저차원 행렬)" 만 추가로 학습하는 방법이다.

- $X$: 입력텐서 ($X \in R^{b*h}$)
- $W$: 전체 파라미터 ($W \in R^{h*o}$)
- $L_1$: 차원을 축소하는 projection (down-projection) ($ L_1 \in R^{h*r}$)
- $L_2$: 차원을 확장하는 projection (down-projection) ($ L_2 \in R^{r*o}$)
Memory Requirement of Parameter-Efficient Finetuning
LoRA 는 학습해야 할 파라미터 수를 줄인 혁신적인 PEFT 방식이지만, 실제 파인튜닝에서는 파라미터 자체보다 학습 중 생성되는 중간 계산값(activation gradients)이 훨씬 더 많은 메모리를 차지한다. 예를 들어, FLAN v2 데이터셋으로 학습하는 7B LLaMA 모델에서는 LoRA 파라미터가 원래 모델의 약 0.2% 수준인 26MB 에 불과하지만, input gradients 는 567MB 를 차지한다. 중간 activation 값을 저장하지 않고 필요할 때마다 다시 계산하는 gradient checkpointing 기법을 적용하면, input gradients 를 567MB 에서 18MB 로 크게 줄일 수 있다.
이를 통해, LoRA parameter 를 더 줄이는 것은 전체 메모리에서 큰 효과가 없고, 그 대신 adapter 수를 늘려 성능을 높이더라도 메모리 부담은 크지 않다는 것을 알 수 있다. 이런 설계가 full 16-bit precision 성능 복원에 핵심적인 역할을 한다.
# QLoRA Finetuning
1. 4-bit NormalFloat Quantization
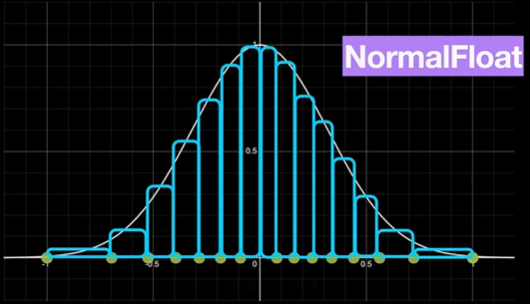
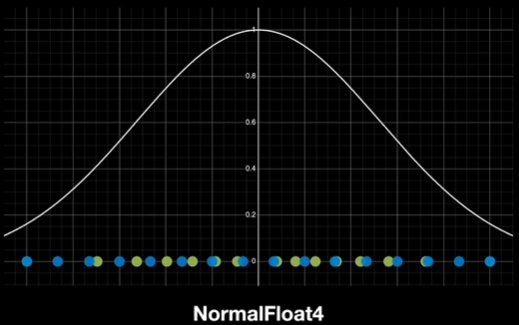
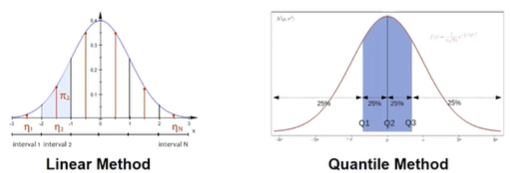
모델의 weight 분포 특성을 활용해서 효율적이고 정확하게 4-bit 양자화 를 수행하는 방법이다.
- 일반적인 양자화는 균일하게 값을 나누지만, 모델 weight 는 대부분 정규분포(Normal Distribution) 를 따르므로 비효율적이다.
- NormalFloat 은 분포에 맞춰 비트를 배분하여 자주 등장하는 값 근처는 더 촘촘하게, 희귀한 값은 적게 비트를 사용한다.
양자화 단계
1. 이론적인 정규분포 $N(0,1)$에 대해 $2^k+1$개의 quantile을 미리 계산한다. -> k-bit 양자화용 데이터 타입 완성
: 매번 모델 weight에 따라 계산하지 않아도 되므로 빠르고 효율적이다
2. 이 quantile들을 [-1,1] 범위로 정규화한다.
3. 입력 weight tensor 도 absolute max rescaling을 통해 [-1,1] 범위로 맞춘다.

대칭적인 k-bit quantization 방식에서는 0 값을 정확히 표현할 수 없는 문제가 있다
하지만 패딩(padding)이나 다른 0 값 요소들을 오차 없이 양자화하려면 0 값의 정확한 표현이 매우 중요하다.
이를 해결하기 위해 우리는 비대칭(asymmetric) 데이터 타입을 사용한다.
구체적으로, 음수 구간에는 $2^{k-1}$ 개, 양수 구간에는 $2^{k-1} + 1$개의 분위수를 추정한다.
그 후 이 두 분위수 집합을 통합하고, 양수와 음수 구간에서 중복된 0 은 하나 제거한다.
그 결과로, 모든 $2^{k}$ 비트를 활용하면서도 bin 마다 기대값이 동일하도록 배분된 데이터 타입을 만들 수 있고, 이러한 데이터 타입을 k-bit NormalFloat (NFk) 라고 부른다.
2. Double Quantization
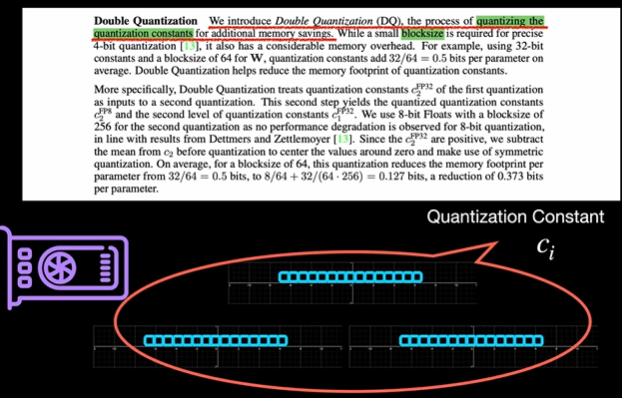
Double Quantization (DQ) 은 양자화 상수 자체를 다시 한 번 양자화해서 메모리 사용량을 추가로 줄이는 기법이다,
배경
원래 weight 양자화 시, 각 블록마다 양자화 상수 (scale factor) 가 필요하다.
하지만 블록 사이즈가 작을수록 정밀도는 좋아지지만, 양자화 상수 개수가 많아져서 메모리 오버헤드가 발생한다.
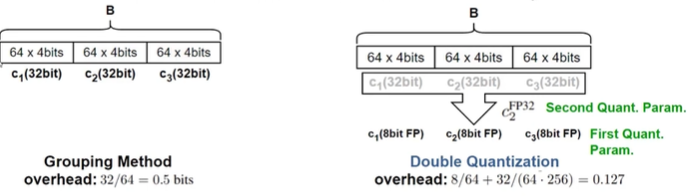
(ex. 32-bit 상수 사용, 블록 사이즈 64 → 평균 파라미터당 0.5 bit 소모)
1. 1단계: 기본 weight 양자화 (1차 양자화)
원래 float weight를 quantization하려면 scale factor가 필요하다
$w_{int} = round(w_{fp32}/c_2)$
- $c_2$: block마다 존재하는 scale factor(quantization constant)
- $c_2$ 들을 저장해야 하는데, 보통 FP32 (32-bit float) 로 저장한다.
block size가 64라고할 때,
$32 bits / 64 parameters = 0.5bits/parameter$
2. 2단계: scale factor 도 양자화 (2차 양자화)
$c_2$ 또한 block으로 묶어 양자화하는게 바로 double quantization > 저장 비용을 더 줄일 수 있다.
$c_{2}^{int8}= round(c_2 -\mu_{c_2}/c_1)$
- $c_{2}^{int8}$: 양자화된 $c_2$, 8-bit로 저장
- $\mu_{c_2}$: $c_2$들의 평균 (mean clustering)
: 평균을 빼는 이유) $c_2$ 가 양수 값이므로, 대칭적으로 만들어서 quantization 효율 높임 - $c_1$: 두 번째 quantization의 scale factor
효과
block size가 64라고할 때,
메모리 절감: $32/64 = 0.5 bits$ -> $8/64 + 32/(64 · 256) = 0.127 bits$
$c_2$를 또 block으로 묶어서 양자화함.
$c_2$들을 256개씩 묶어서
scale factor $c_1$ 1개
양자화된 $c_2^{int8}값 256개
평균적으로 파라미터당 0.373 bit 절약할 수 있다.
3. Paged Optimizers

Paged Optimizer 는 NVIDIA Unified Memory 기능을 활용한다. 이 기능은 GPU 메모리가 부족할 때, CPU 메모리(RAM) 와 GPU 메모리 간에 자동으로 "페이지 단위 전송(page-to-page transfer)" 을 해주는 기능이다.
쉽게 말하면:
- 우리가 보통 PC 에서 RAM 이 부족하면, 디스크(HDD/SSD) 로 스와핑이 일어나듯이
- GPU 메모리가 부족하면, CPU RAM 으로 자동으로 데이터를 옮겼다가 필요할 때 다시 가져오는 방식이다.
# QLoRA
QLoRA Linear Layer 원리

- 저장 시:
- Weight: 4-bit NormalFloat (NF4)
- Scale factor: Double Quantization (block size 256)
- 계산 시:
- 복원된 BF16 precision 으로 연산
- LoRA adapter (BF16) 를 통해 fine-tuning
- gradient:
- base weight 에 대해 gradient 저장 안 함
- adapter weight 에 대해서만 gradient 저장
# Evaluation
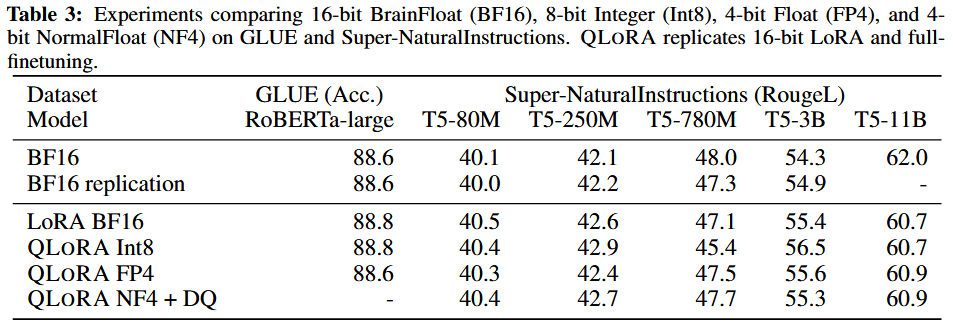
QLoRA를 통해 메모리를 많이 줄였는데도 점수가 거의 차이가 없다는 것을 볼 수 있었다.
Reference
시각적으로 도움을 받은 영상
https://www.youtube.com/watch?v=6l8GZDPbFn8
https://www.youtube.com/watch?v=aZPAqBov3tQ
https://www.youtube.com/watch?v=XpoKB3usmKc