0. Abstract
최근 대형 언어 모델(LLM)의 폭발적인 발전과 함께, 그 능력을 시각 영역으로 확장하려는 시도가 활발히 이루어지고 있다.
VLM(Vision-Language Model)은 고수준의 텍스트 설명만으로 이미지를 생성하거나, 시각적 장면을 언어로 이해하는 등
우리의 기술 환경에 큰 변화를 가져올 응용 가능성을 보여주고 있다.
하지만 시각 정보는 언어와 달리 고차원 연속 공간에 존재하며, 개념을 명확히 구분하거나 표현하기 어렵다는 근본적인 특성이 있다. 따라서 시각 정보를 언어로 정확히 연결(mapping)하는 데에는 여전히 많은 기술적 과제가 남아 있다.
본 논문은 이러한 배경 속에서, VLM의 개념과 학습 방법, 평가 방법을 소개하는 입문서로 기획되었다.
특히 이미지를 넘어서 비디오까지 확장되는 흐름을 염두에 두고, 비전-언어 연구를 시작하려는 연구자에게 유용한 기본기를 제공하고자 한다.
1. Introduction
VLM은 왜 중요한가?
언어 모델은 점점 더 똑똑해지고 있지만, 여전히 현실을 보는 능력은 부족하다.
시각 정보는 텍스트와 달리:
- 불연속(discrete)한 언어와 달리 고차원 연속 공간
- 구체적 개체 + 추상적 관계 + 위치/형태/수량 등 복합 정보 포함
VLM은 이처럼 복잡한 시각 정보를 텍스트 표현으로 매핑함으로써
AI의 현실 이해력과 상호작용 능력을 비약적으로 끌어올릴 수 있다.
하지만 VLM은 아직 갈 길이 멀다
- 대부분의 VLM은 정확한 수량 추론이나 공간 관계 이해에 취약
- 속성(attribute)이나 순서(ordering) 개념도 잘 반영하지 못함
- 프롬프트를 일부 무시하거나, 전혀 상관없는 결과(=hallucination)를 생성하기도 함
→ 안정적이고 신뢰할 수 있는 VLM 개발은 여전히 중요한 연구 과제인 상태
이 논문은 어떤 내용을 다루는가?
이 논문은 다음 내용을 입문자 친화적인 흐름으로 설명합니다:
- VLM의 개념 및 구조
- contrastive 방식, masked 방식, generative 방식 등 VLM의 계보 구분
- LLM 기반 사전학습(backbone 사용)에 대한 설명
- VLM 학습 전략
- 어떤 데이터셋을 써야 할까?
- 텍스트 인코더는 새로 학습해야 할까? LLM을 가져와 쓸 수 있을까?
- contrastive loss만으로 충분한가? generative 요소도 필요할까?
- VLM 평가 방법
- visio-linguistic benchmark의 현황과 한계
- bias를 어떻게 측정할 것인가?
- VLM의 미래: Video로의 확장
- 이미지와 달리 영상은 시간 축(temporal) 이해가 필요
- 연산량, 어노테이션 비용 등 새로운 도전 과제 제시
2. The Families of VLMs
트랜스포머(Transformer) 기반의 아키텍처가 도입된 이후, 시각과 언어를 연결하려는 다양한 연구들이 시도되었다.
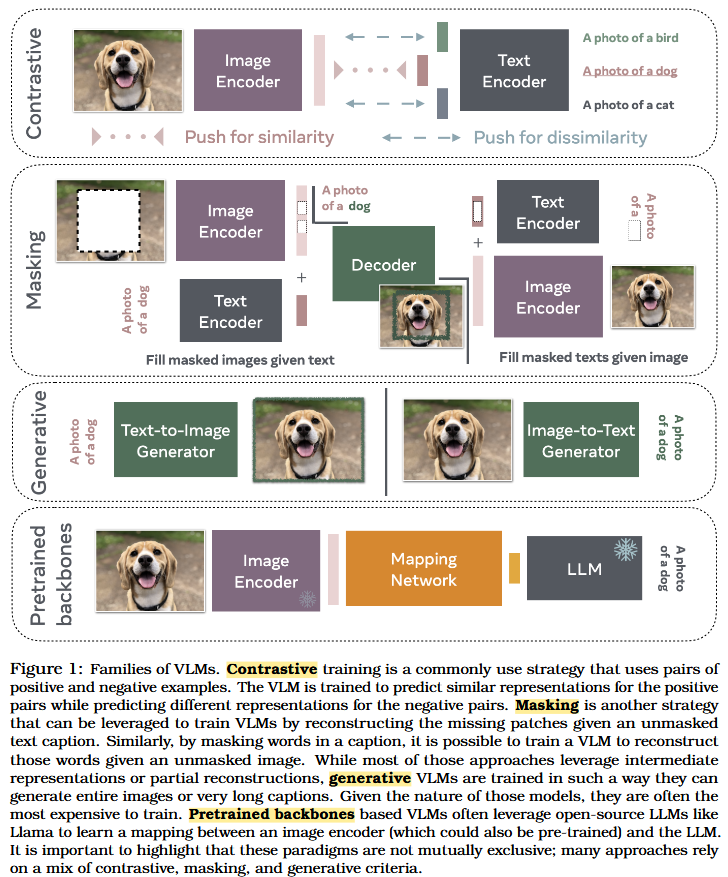
(1) contrastive learning (2) masking (3) pretrained backbones (4) generative modeling
이 장에서는 최근의 VLM들을 학습 방식에 따라 네 가지 패러다임으로 나누어 소개한다.
이 네 가지 방식은 상호 배타적인 것이 아니며, 많은 모델들은 여러 방식을 혼합하여 사용하기도 한다.
2.1 Early work on VLMs based on transformers
초기의 VLM 연구에서는 BERT와 같은 언어 모델을 시각 정보에 확장하여 사용했다.
예를 들어, VisualBERT와 ViLBERT는 이미지 토큰과 텍스트를 결합하여 시각-언어 간의 상호작용을 학습했다.
이러한 모델들은 두가지 objective를 사용하여 학습된다.
(1) classical masked modeling: 입력의 일부(텍스트나 이미지)를 가리고, 모델이 이를 정확히 예측하도록 학습
(2) sentence-image prediction: 주어진 캡션이 이미지와 실제로 관련 있는지 아닌지를 모델이 이진 분류로 판단
2.2 Contrastive-based VLMs
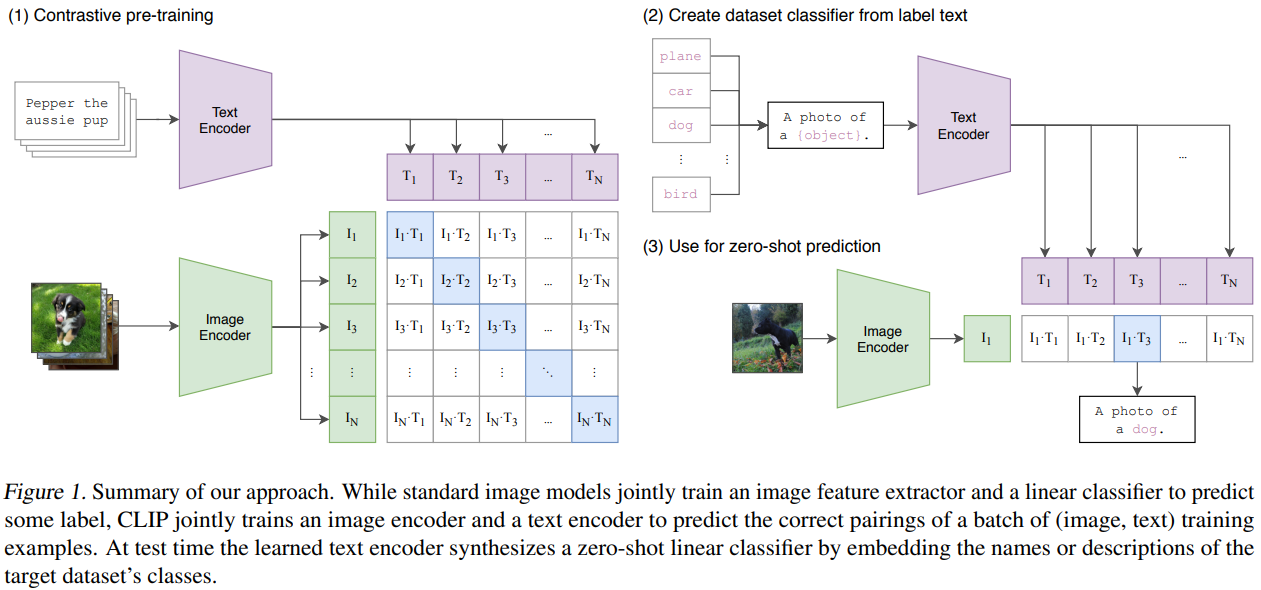
CLIP (Radford et al., 2021)은 대조 학습 기반 Vision-Language Model 중 가장 널리 알려진 대표적인 모델이다.
이 모델은 InfoNCE 손실 함수를 활용해 이미지와 텍스트 간의 쌍을 학습하여, 공동 임베딩 공간(shared embedding space)에서 의미적으로 유사한 이미지-텍스트가 가까이 위치하도록 만든다.
- Positive pair:
- 한 이미지와 해당 이미지에 대한 정답 캡션
- Negative pair:
- 동일한 이미지와 다른 이미지들의 캡션들
- 즉, 미니배치 안에 있는 나머지 모든 문장들과의 조합은 부정 샘플로 간주
CLIP은 웹에서 수집한 4억 개의 이미지-캡션 쌍으로 사전 학습되었고, 다음과 같은 강력한 제로샷 성능을 보인다:
- ResNet-101 기반 CLIP은 supervised ResNet-101과 유사한 성능 달성 (예: ImageNet에서 76.2%)
- 다양한 robustness benchmark에서도 기존 지도 학습 모델을 능가
후속연구
🔸 SigLIP (Zhai et al., 2023)(ICCV'23 Oral)
- CLIP과 유사하지만, InfoNCE가 아닌 binary cross-entropy 기반 NCE 손실을 사용함
- 이를 통해 작은 배치 크기에서도 안정적인 제로샷 성능을 보여줌
- 특히 대규모 리소스 없이도 학습 가능한 대안으로 주목받음

https://x.com/giffmana/status/1692641733459267713
🔸 LLiP (Lavoie et al., 2024)
- 하나의 이미지에 여러 방식의 캡션이 가능하다는 현실을 반영
- 이미지 인코딩을 캡션에 조건(condition) 하도록 cross-attention 모듈을 추가함
- 표현력 향상 → 제로샷 분류 및 이미지-텍스트 검색 성능 향상

2.3 VLMs with masking objectives
FLAVA
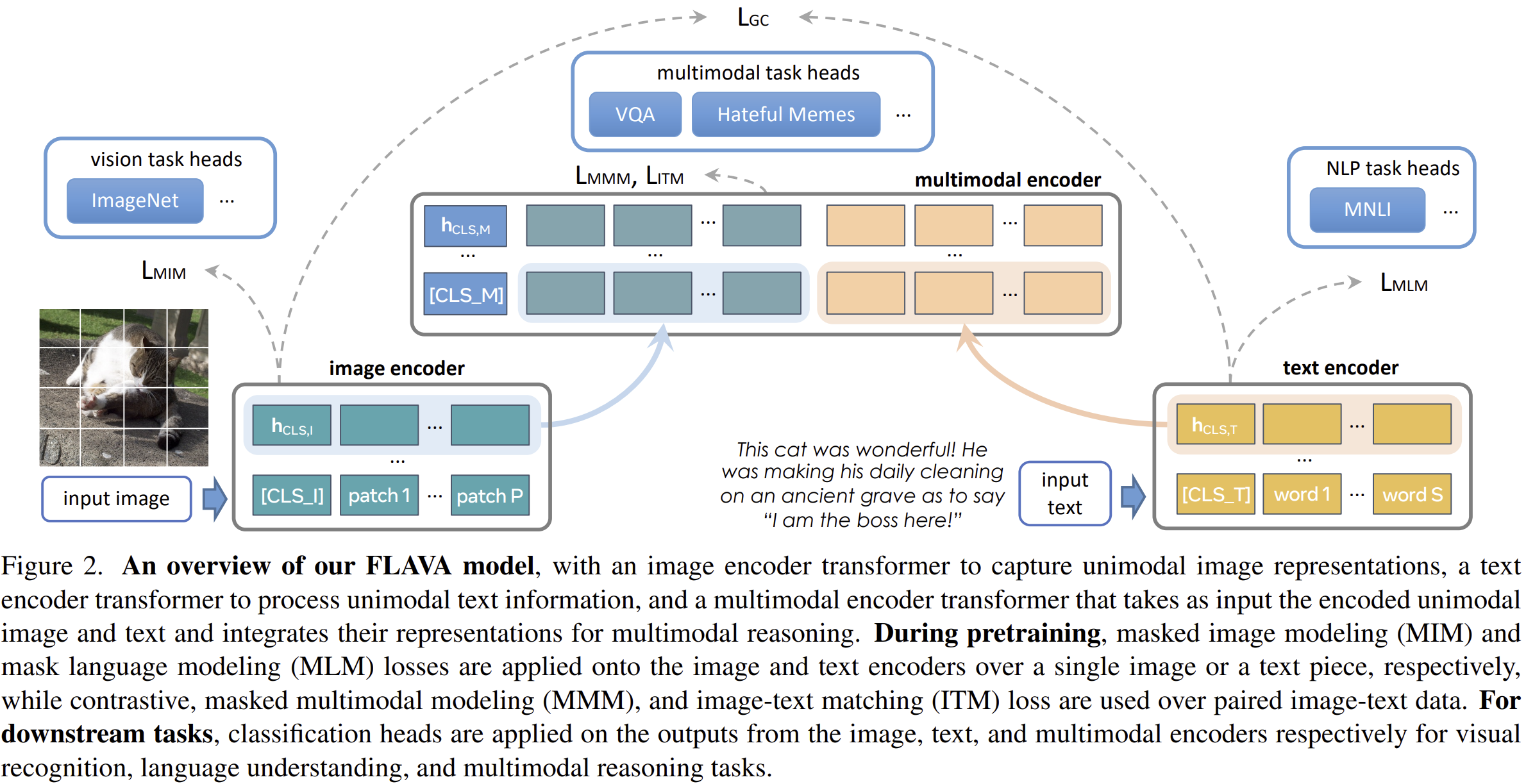

이미지와 텍스트 모두에서 masking 기법을 활용해 학습한 대표적인 멀티모달 모델
FLAVA는 세 개의 Transformer 기반 모듈로 구성되어 있다:
- Image Encoder
- ViT 기반
- 이미지 패치를 입력으로 받아 [CLS_I] 토큰 포함 출력
- Text Encoder
- 문장을 토큰화하여 [CLS_T] 토큰 포함 출력
- Multimodal Encoder
- 이미지와 텍스트의 출력(hidden states)을 통합
- cross-attention과 선형 투영을 활용해 [CLS_M] 토큰 포함 출력
FLAVA는 다음 세 가지 학습 손실을 결합하여 사전 학습을 진행한다:
- Unimodal Masked Modeling Loss: 이미지 또는 텍스트 단독으로 마스킹된 정보를 예측
- Multimodal Masked Modeling Loss: 이미지와 텍스트 정보를 함께 사용해 마스킹된 내용을 예측
- Contrastive Objective: 올바른 이미지-텍스트 쌍은 가깝게, 그렇지 않은 쌍은 멀게 임베딩되도록 학습
FLAVA는 7천만 개의 공개 이미지-텍스트 쌍으로 사전학습되었으며, 총 35개의 다양한 비전/언어/멀티모달 벤치마크에서 강력한 성능을 보여주었다.
MaskVLM
FLAVA의 단점은 dVAE같은 pretrained vision encoder를 사용했다는 것이다.
이처럼 타사 구성 요소에 대한 의존성을 가지면 완벽한 end-to-end 학습이 어렵게 되는 단점이 존재한다.
이를 해결하기 위해 아래의 모델을 제안한다.
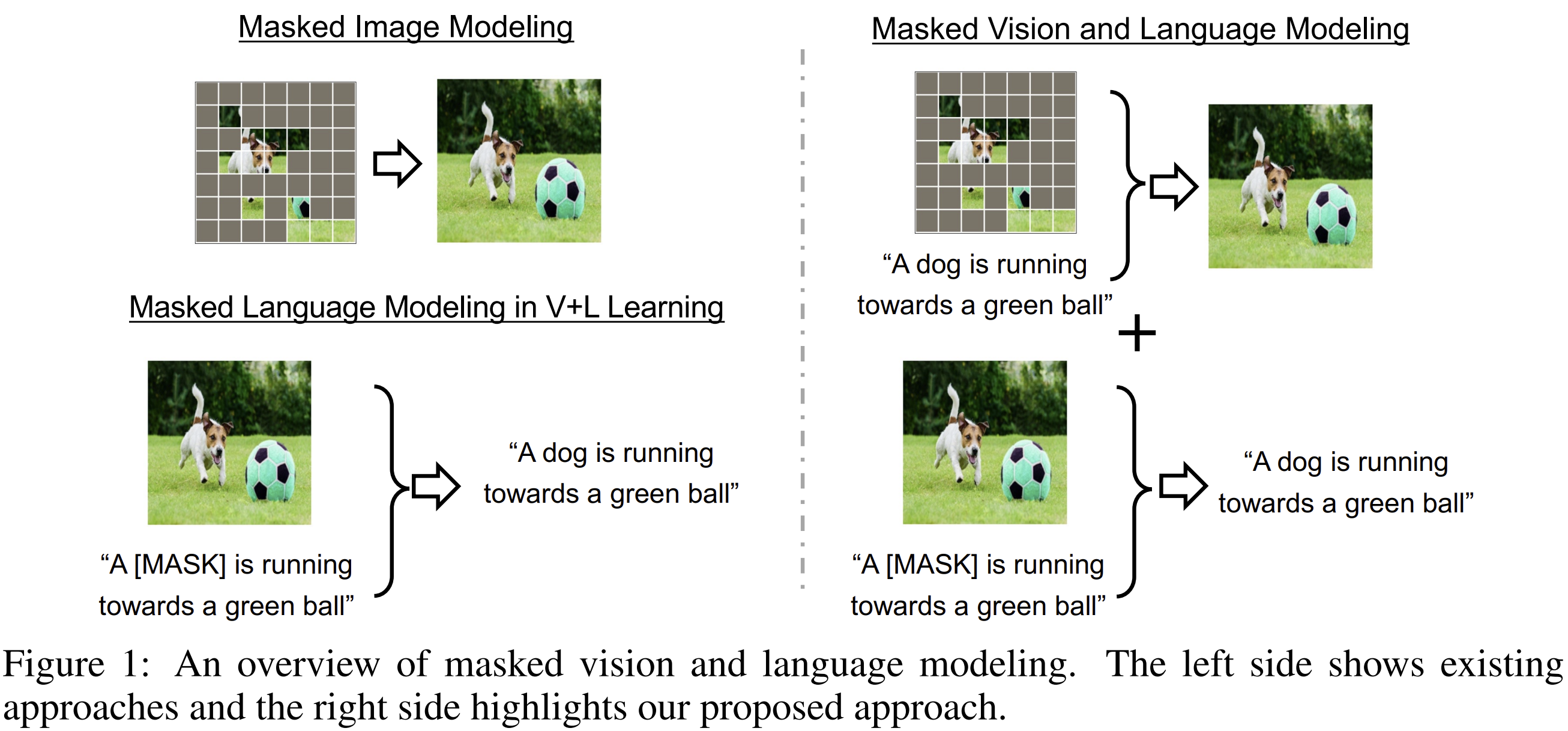

- 픽셀 공간에서의 직접적인 마스킹
- 이미지를 patch 단위로 나누지 않고, 원본 이미지의 raw pixel에 직접 마스킹을 적용한다.
- 이는 VAE 없이 이미지 정보를 직접 재구성하도록 유도한다는 점에서 end-to-end 학습이 가능해진다.
- 텍스트 토큰에 대한 마스킹
- 이미지뿐만 아니라, 텍스트 입력도 일부 단어를 마스킹한 후 복원하는 Masked Language Modeling (MLM) 방식 적용.
- 크로스모달 정보 흐름의 활용
- 텍스트를 복원할 때 이미지 인코더에서 나온 시각 정보를 사용하고,
- 이미지를 복원할 때 텍스트 인코더에서 나온 언어 정보를 사용하는 양방향 정보 흐름 구조를 도입.
- 즉, 한 modality에서 누락된 정보를 다른 modality로부터 보완하여 복원한다.
2.4 Generative-based VLMs
지금까지 소개된 VLM들은 대부분 잠재 표현(latent representation) 수준에서 이미지와 텍스트를 추상화한 뒤, 이를 매핑하는 방식으로 학습되었다. 반면, Generative-based VLMs는 텍스트와 이미지를 직접 생성할 수 있는 모델을 의미한다. 이들 모델은 이미지 캡셔닝, 텍스트 생성, 이미지 생성 등 다양한 방식으로 비전-언어 작업을 수행하며, 특히 multi-modal generation에 강점을 가진다.
Coca: 텍스트 생성 기반

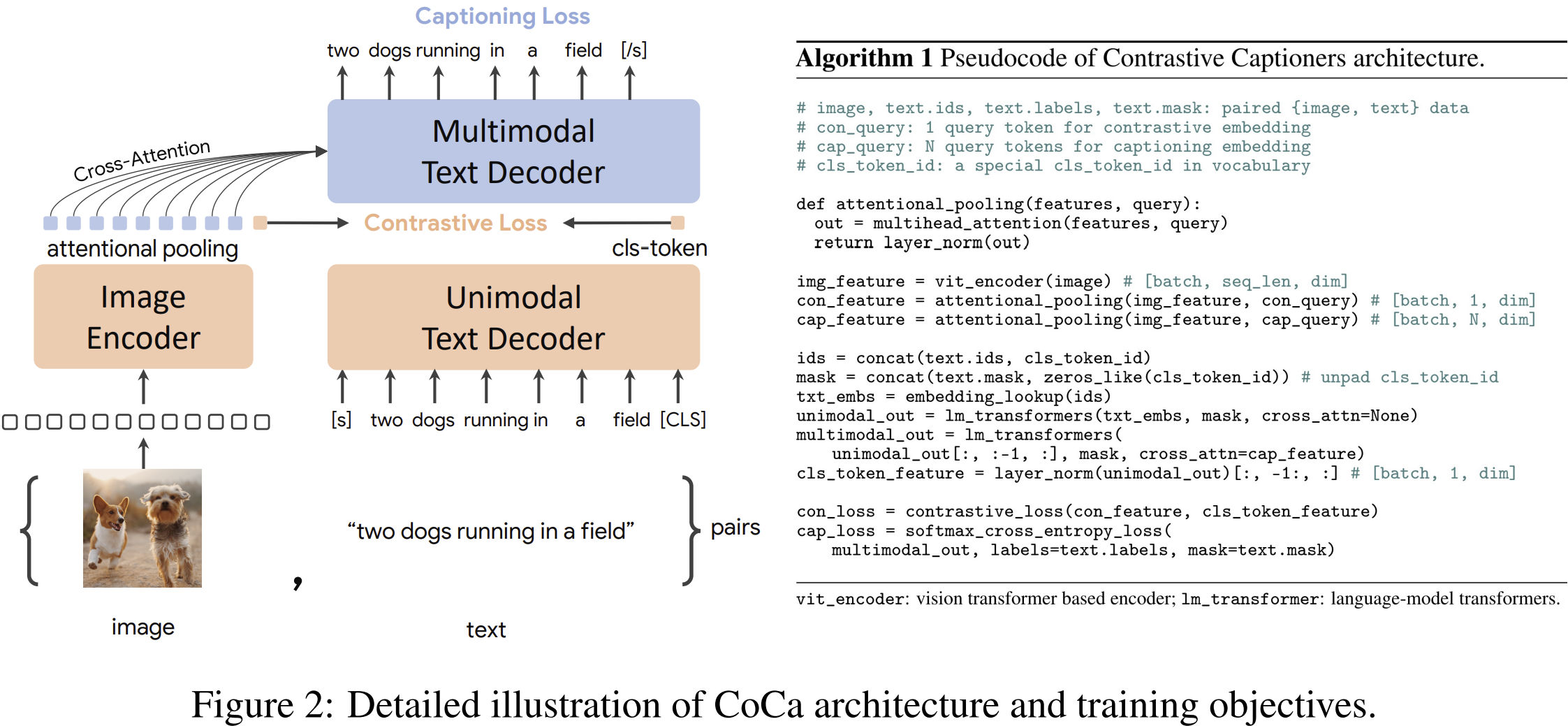
CoCa (Contrastive Captioner)는 CLIP에서 사용된 contrastive loss에 generative loss를 추가하여, 이미지 캡셔닝 및 VQA(Visual Question Answering) 같은 작업도 처리할 수 있도록 설계된 모델이다.
- 입력: 이미지 인코더의 출력과 텍스트 디코더의 중간 표현
- 출력: 멀티모달 텍스트 디코더가 생성한 캡션
- 학습 손실: contrastive loss + caption generation loss
구분/입력/목적/출력
| Image Encoder | 이미지 | 시각 정보 인코딩 | img_feature |
| Unimodal Text Decoder | 텍스트 + [CLS] | contrastive 용 텍스트 임베딩 | cls_token_feature |
| Multimodal Text Decoder | 텍스트 + 이미지 context (cap_feature) | 이미지 설명 생성 | 단어 시퀀스 |
CoCa는 이미지의 라벨을 텍스트로 처리하는 방식으로 학습되며, 대규모 웹 기반 데이터셋인 ALIGN (1.8B 이미지)와 내부 라벨 데이터셋인 JFT-3B (>29.5K 클래스)로 학습된다. 이로 인해 별도의 멀티모달 모듈 없이 다양한 비전-언어 태스크를 수행할 수 있다.
Chameleon and CM3leon: 멀티모달 생성 모델
CM3Leon (Meta AI, 2023)
CM3Leon은 텍스트-이미지 간 양방향 생성(image captioning + text-to-image generation)을 모두 수행하는 multimodal autoregressive model이다.

- 토크나이저 구성:
- 이미지: 256×256 이미지를 1024개의 시각 토큰으로 변환
- 텍스트: 기존 텍스트 토크나이저 사용 (vocab size 56,320)
- 특별 토큰 <break>로 modality 전환 시점을 명시
- 모델 구조: Decoder-only Transformer
- 학습 과정:
- Retrieval-augmented pretraining: CLIP 기반 retriever로 관련 문서들을 불러와 시퀀스 앞에 붙여 학습
- Supervised fine-tuning (SFT): multi-task instruction tuning 방식으로 다양한 태스크 학습
CM3Leon은 텍스트-이미지 간 상호작용을 자연스럽게 처리할 수 있는 능력을 보여주며, 다양한 멀티모달 태스크에서 SOTA 성능을 달성하였다.
Chameleon (OpenAI, 2024)
Chameleon은 텍스트, 이미지, 코드가 하나의 연속된 시퀀스로 처리되는 진정한 Mixed-modal Foundation Model이다.
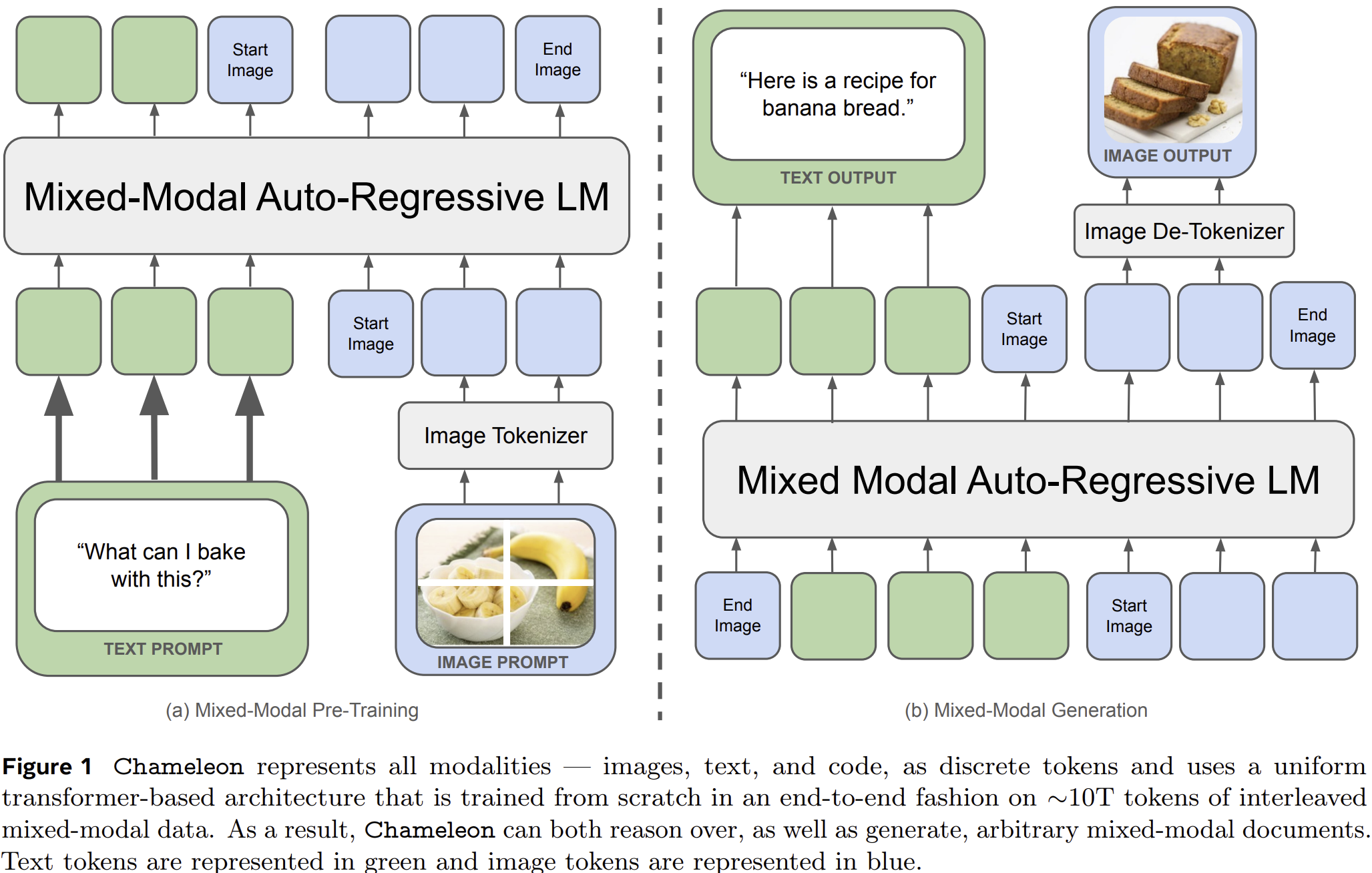
- 입력 단일화: 이미지와 텍스트 모두 discrete 토큰으로 변환해, 동일한 Transformer로 처리
- 아키텍처 특성:
- Early-fusion 구조: 모든 modality를 처음부터 하나의 공간에 매핑
- Fully token-based: encoder 분리 없이 통합 표현
- 기술적 도전과 해결:
- Query-key normalization, layer norm 위치 조정 등으로 안정성 확보
- 기존 텍스트 기반 SFT 기법을 mixed-modal에도 적용
Chameleon은 일반적인 이미지 생성이나 캡셔닝을 넘어, 다중 모달 문서 이해 및 생성까지 수행할 수 있는 강력한 범용 모델로 주목받고 있다.
+ Early Fusion 방식은 Gemini에서도 사용되었지만, gemini는 이미지와 텍스트에 대해 별개의 디코더를 사용한 반면에 Chameleon은 디코더 부분까지 통합된 모듈로 엔드 투 엔드로 동작한다는 차이점이 있다.
(출처: https://kk-eezz.tistory.com/109)
2.5 VLMs from Pretrained Backbones
Vision-Language Model(VLM)을 처음부터 학습하는 것은 막대한 리소스를 요구한다.
수백~수천 개의 GPU와 수억 개의 이미지-텍스트 쌍이 필요하기 때문에, 최근에는 이미 학습된 LLM이나 비전 인코더를 재활용하는 방식이 주목받고 있다.
이 절에서는 대표적인 pretrained backbone 기반 VLM들을 소개한다.
Frozen
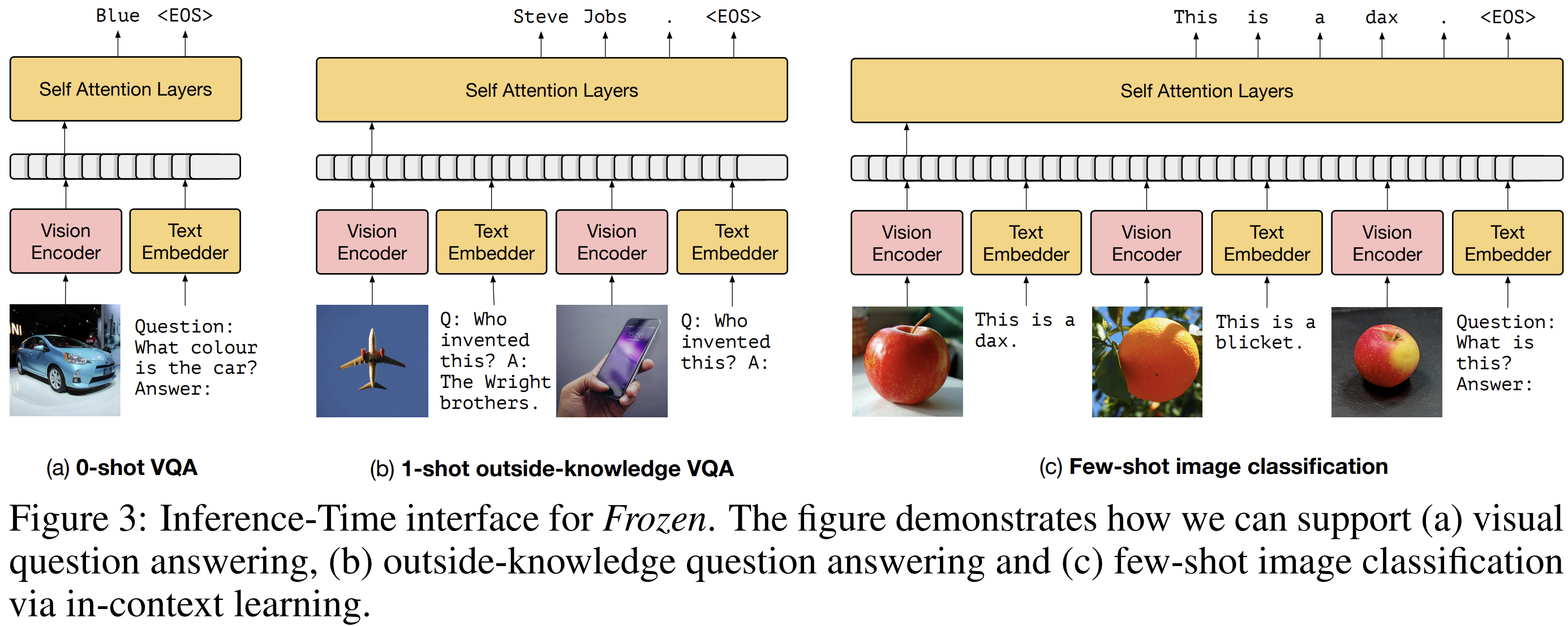
- Frozen은 사전학습된 LLM(7B 파라미터)과 가벼운 vision encoder를 연결하는 최초의 시도 중 하나
- 구조:
- Vision encoder: NF-ResNet-50 (학습됨)
- Language model: 7B transformer (C4로 학습된 상태 그대로 freeze)
- 두 모달리티 사이를 선형 매핑 layer로 연결
- 학습:
- Conceptual Captions 데이터셋 기반 텍스트 생성 목표로 학습
- 특징:
- 이미지와 텍스트 임베딩을 함께 입력받아 텍스트를 생성
- 성능은 제한적이지만, 멀티모달 LLM의 기반을 마련한 의미 있는 출발점
MiniGPT 계열
MiniGPT-4
- Flamingo 이후 발전한 구조로, 텍스트와 이미지를 입력으로 받아 텍스트를 출력함
- 구성:
- Visual encoder: BLIP-2의 ViT + Q-Former
- Language model: Vicuna
- 중간 연결: 단순한 선형 projection layer
- 학습:
- 1단계: Conceptual Captions, SBU, LAION (5M쌍)으로 선형 레이어 학습 (4GPU, 10시간)
- 2단계: instruction tuning 방식의 소규모 고품질 데이터 (400 step)
- 장점: 사전학습된 백본을 활용하여 매우 효율적으로 학습 가능

MiniGPT-5
- MiniGPT-4에서 이미지도 출력 가능한 모델로 확장
- 이미지 생성을 위해 generative visual token 사용 → Stable Diffusion 2.1에 입력됨
- 멀티모달 대화, 스토리 생성 등 복합 태스크에 활용

MiniGPT-v2
- 다양한 비전-언어 태스크를 하나의 인터페이스에서 처리
- 각 태스크에 대해 고유 태스크 식별자(token)를 추가하여 멀티태스크 학습 효과적으로 달성
- VQA, visual grounding 등에서 우수한 성능

그 외 대표적인 백본 기반 모델
Qwen-VL / Qwen-VL-Chat
- 구조:
- LLM: Qwen-7B
- Visual encoder: ViT-bigG
- Cross-attention으로 visual feature를 압축 후 LLM에 입력
BLIP-2
- 구조:
- Visual encoder (예: CLIP) → image embedding
- Q-Former: randomly initialized query vector들이 이미지 임베딩과 cross-attention 수행
- 결과를 선형 변환하여 LLM의 입력 공간으로 투영
- 특징:
- LLM(예: OPT)은 freeze 상태
- Q-Former만 학습 → 효율적이며 성능 좋은 구조
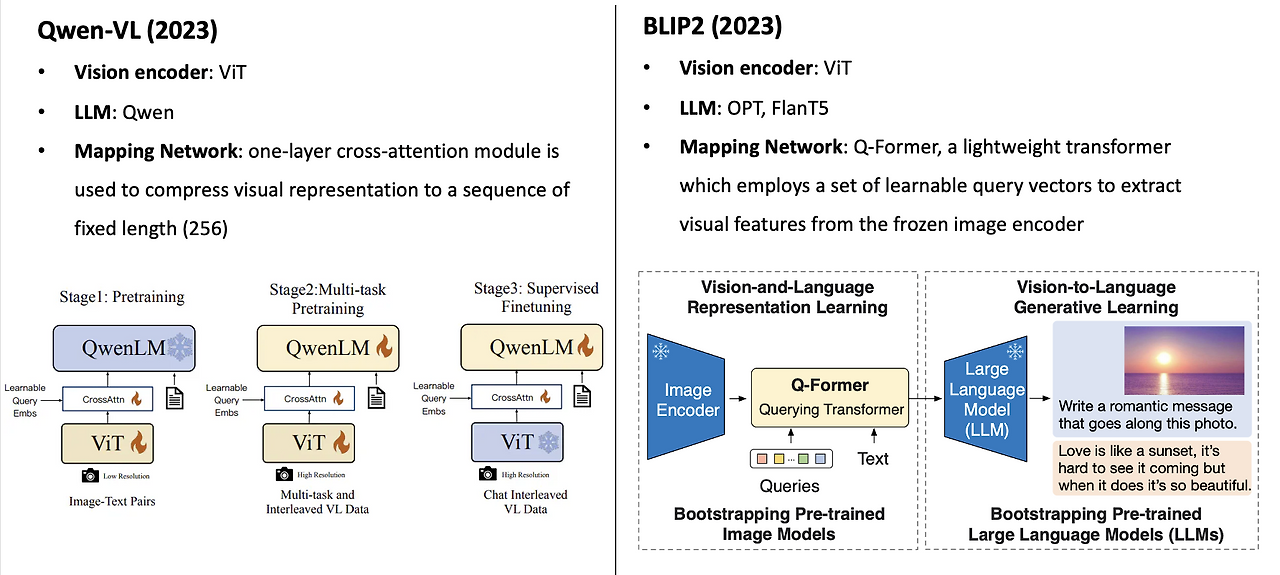
Q-former이란?
"Query Transformer"의 약자로, 학습 가능한 쿼리(query) 벡터들을 사용해 이미지와 상호작용하고,
이를 통해 얻은 정보를 LLM의 입력 토큰 공간으로 매핑하는 역할을 수행
왜 Q-Former가 필요한가?
LLM은 텍스트 토큰만을 입력으로 받도록 설계되어 있다.
하지만 이미지 인코더가 출력하는 feature는 LLM의 기대하는 embedding space와 다릅니다.
>>> Q-Former는 이 간극을 bridge(다리) 해주는 역할
Q-Former의 구조와 작동 방식
① 입력
- Image encoder (예: ViT)로부터 추출한 image feature tokens
- 학습 가능한 query vector (예: 32개, 랜덤 초기화)
② Transformer 기반 cross-attention
- Query vector들이 image tokens과 cross-attention을 수행함 (즉, "이 이미지에서 중요한 정보가 뭐야?"를 query들이 묻는 구조)
- 이 과정을 통해 query들은 이미지 정보가 녹아든 벡터로 업데이트됨
③ Projection to LLM input space
- 위에서 얻은 query 출력을 선형 projection layer를 통해 LLM의 입력 포맷으로 변환
- 이때 나온 벡터들은 텍스트 토큰과 동일한 포맷이 되어, LLM에 자연스럽게 연결됨
항목 / Qwen-VL / BLIP-2 (Q-Former 기반)
| 시각 정보 삽입 방식 | 텍스트 토큰 위에 cross-attention으로 시각 정보 반영 | 이미지 피처를 pseudo text token으로 변환하여 LLM에 직접 입력 |
| LLM 입력 구조 | 텍스트만 입력, 이미지 피처는 내부에서 참조만 함 | 이미지 임베딩이 텍스트처럼 직접 입력됨 (Q-Former 통해 변환됨) |
| 학습되는 부분 | Cross-attention layer, LLM 일부 fine-tune | Q-Former (query + cross-attn + projection)만 학습 |
| 디자인 철학 | "텍스트 중심 reasoning + 이미지 보조" | "이미지 요약을 텍스트화해서 LLM에게 맡김" |
| 유연성 | 기존 LLM 구조 거의 그대로 유지 가능 | 구조상 LLM과 tightly couple 필요 |
| 텍스트-이미지 결합 시점 | LLM 내부의 attention 레이어에서 결합 | LLM 입력단에서 결합됨 (입력 자체가 멀티모달) |
모델 / 특징 / 연결 방식 / 학습 파라미터
| Frozen | 최초의 LLM 연결 VLM | linear projection | LLM은 freeze |
| MiniGPT-4 | 효율적 텍스트 생성 | linear + BLIP-2 encoder | Vicuna + ViT |
| MiniGPT-5 | 텍스트 + 이미지 생성 | generative visual token + SD 2.1 | 멀티모달 생성 |
| MiniGPT-v2 | unified 인터페이스 + 태스크 식별자 | instruction tuning | VQA 등 강함 |
| Qwen-VL | cross-attention 기반 연결 | ViT-bigG → LLM | Qwen-7B 사용 |
| BLIP-2 | Q-Former로 정렬 | CLIP → Q-Former → LLM | 효율적 구조 |
3. A Guide to VLM Training
최근 VLM(Vision-Language Model)의 성능을 높이기 위해 스케일업이 강조되어 왔다.
CLIP처럼 수억 개의 이미지-텍스트 쌍을 활용한 대규모 학습은 높은 성능을 보장하지만, 막대한 비용과 자원이 소모된다.
하지만 최근 연구들은 단순한 데이터 양의 확장보다는 ‘좋은 데이터셋을 어떻게 선별하고 구성하느냐’가 성능 향상에 더 효과적임을 보여주고 있다.

좋은 데이터가 곧 좋은 제로샷 성능을 만든다
- 제로샷 성능은 "모델이 똑똑해서"가 아니라,
학습 데이터 안에 그 개념이 충분히 포함되어 있었기 때문에 가능한 것 - “학습 데이터에 그 개념이 얼마나 존재하느냐”가 제로샷 성능의 핵심
# 참고 블로그
'📚 Study > Paper Review' 카테고리의 다른 글
| [24'NeurlPs] Visual Fourier Prompt Tuning (0) | 2025.05.09 |
|---|---|
| [Paper Review] Vision-Language Models for Vision Tasks: A Survey (0) | 2025.05.08 |
| [Paper Review] QLoRA: Efficient Finetuning of Quantized LLMs (0) | 2025.04.11 |
| [LLM] Base Model과 Instruct Model, 그리고 Chat Template (0) | 2025.03.27 |
| [Paper Review] Compact3D: Smaller and Faster Gaussian Splatting with Vector Quantization (2) | 2024.07.14 |